如果你曾经在谷歌上搜索过名人、著名的地标或产品,那么你很可能会遇到一些信息框,这些信息框通常位于搜索结果页面的右侧。它们充满了来自谷歌知识图谱的信息,这是一个实体数据库,用来增强网络上的搜索结果,以及像 Google Home 这样的智能语音。大部分的知识图谱都是来自人类团队的众包,他们梳理数百万个网站,寻找关于人、地点和事物的常见问题的答案。
而如果你问 Mike Tung,他会告诉你,现在有一个更好的方法来做这件事。
Mike Tung 是位于美国加州山景城的创业公司 Diffbot 的创始人,该公司的使命是将网络的非结构化数据转换成结构化数据——或者,用 Tung 的话说,“从文档中自动提取知识”。在经过多年的试验后,该项目于近期公开发布。
“我们正试图通过分析互联网上的每一页来创建人类第一个全面的知识图谱。”Tung 在接受采访时说。
这是一个崇高的目标。在斯坦福大学的人工智能研究中成长起来的 Diffbot,花了 5 年时间打造完成它所需的工具。通过利用计算机视觉和自然语言处理的结合,Diffbot 的 Web 爬虫可以解析几乎任何网页的布局和结构——大约 90%的网页和 20 个左右的页面类型——构建事实、数字和对象之间的抽象关系。
“我们称这为知识即服务,”Tung 说。“现在,30%的知识型员工的工作是收集数据。在市场上,有一个关于横向知识图谱的大好机会——一个关于人、企业和事物的信息数据库。”

由 Diffbot 的爬虫提取的数据被输入一个名为“Diffbot 知识图谱”(DKG)的巨大的数据库,它包含了超过 1 万亿的事实和 100 亿个实体。(据 Tung 说,每月增加的事实达 1.3 亿。)核心类别包括人员(技能、就业历史、教育、社会概况)、公司、地点(地图数据、地址、业务类型、分区信息)、文章(每篇新闻文章、日期行、来自网络上任何地方的任意语言的署名)、讨论(聊天、社交分享和对话)和图像(使用图像识别和元数据收集组织)。
所有这些都可以通过 API 调用访问,并通过 Diffbot 的自定义查询语法进行操作。客户端可以在 Diffbot 基于 Web 的 UI 中查看来自 DKG 的结果,或者在第三方内容管理系统或分析平台中查看结果。
目前的客户有微软、eBay、Yandex 和 DuckDuckGo,它们正利用这一服务来提高搜索结果的质量。其他客户包括 Cisco、Salesforce、Crunchbase、Hubspot、Adobe、Instapaper 和 Onswipe。
“简单地说,Diffbot 正在利用人工智能的力量,这是我们以前从未见过的,” Diffbot 投资者之一 Felicis Ventures 的创始人兼董事总经理 Aydin Senkut 说。“这是有史以来第一家盈利的人工智能公司;它们为科技行业的许多大公司提供应用的‘秘密成分’”。
在一个演示中,Tung 展示了它是如何工作的。假设你想对某品牌的踪迹进行一次性的搜索。在 Diffbot 的 Web 控制面板中,你可以将运动鞋品牌输入到一个类似谷歌的搜索栏中,然后点击进入;在几毫秒内,你就会得到一个由网络上的源合成的产品概要。
寻找新闻报道?同样的过程:输入作者的名字会产生他们在网上发布的每一篇文章(跨语言)。另一方面,寻找一个人,从几十个(或数百个)的 bios、文章和公共可用的个人资料中拼凑出一个类似 CV-A 的工作历史。
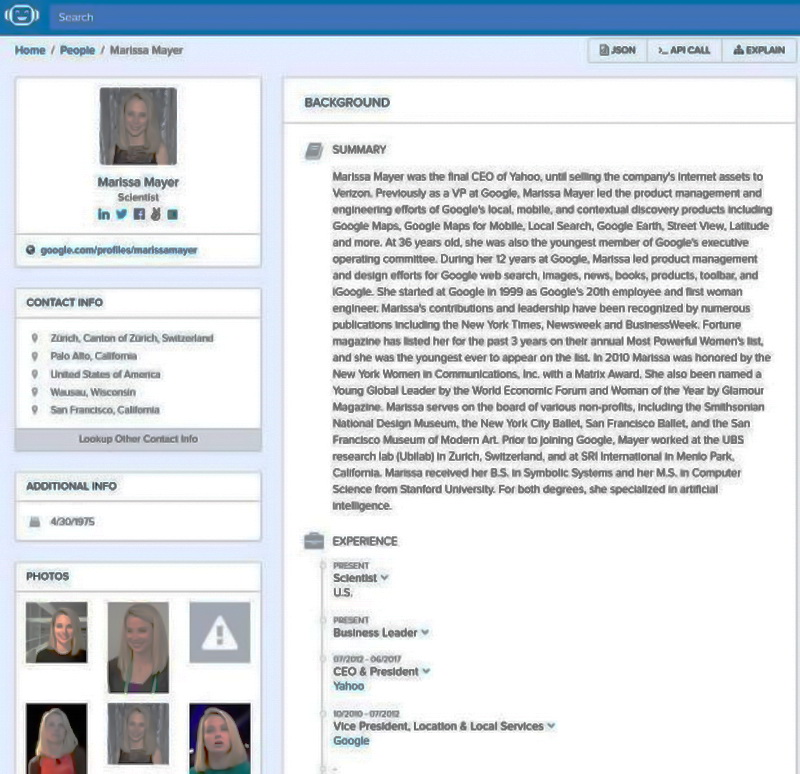
Tung 解释说,Diffbot 的独特优势之一是它能够迅速地通过实体进行“钻探”。它在招聘等任务中也很有帮助——适当的 DQL 字符串可以对某公司的每一个员工进行整理,并将他们的工作头衔、技能、教育背景和社交媒体资料放在一个地方。
“这是机器学习的圣杯——在一个地方捕捉到世界上所有的知识。”Tung 说。
从历史上看,谷歌的知识图谱因缺乏属性和遗漏信息来源而受到批评,但 Tung 说,Diffbot 的自动方法一举解决了这两个问题。Diffbot 不仅比像 Google 的知识图谱这样的人工精选数据库更全面,而且它也更准确——Diffbot 的爬虫会定期用新信息刷新 DKG,它的机器学习算法足够智能,可以分析有“逻辑上不一致”历史记录的站点。
“这就是为什么我们将信息从不同来源融合在一起的原因之一,”Tung 说。“我们的规模使得错误的可能性极小。”
该公司于 2008 年推出,核心员工有 28 名,其中包括工程师和数据科学家。此前,该公司在一轮融资中获得了 1000 万美元的融资,领投的是风险投资公司腾讯、Felicis Ventures 和 Amplify Ventures。
【数字叙事 原作:KYLE WIGGERS;编译:小即】

